Build AI Agents with Strands: Multi-Agent Orchestration Architecture (Part 1)
Learn how to build production-ready AI agents using multi-agent orchestration. Part 1 of the Deep Agents series explores why shallow agents fail and how specialized sub-agents enable scalable AI systems.
Shallow agents work great until they don't. And when they fail, they fail hard — losing important context, forgetting objectives, or becoming overwhelmed by complexity.
📚 The Deep Agents Trilogy
This is Part 1 of a three-part series on building production-ready AI agent systems.
#1 Foundations — You are here: Understanding deep vs shallow agents and multi-agent orchestration
#2 Building DeepSearch — Implement a multi-agent research system from scratch
#3 Production Deployment — Deploy to Amazon Bedrock AgentCore with LangFuse observability (infrastructure handled with Terraform modules)
It's hardly a secret anymore: we are now living in the era of agents
This evolution began with what we can now call shallow agents: simple agents widely adopted across companies to handle a range of tasks. These agents have proven sufficient for basic problems — but as soon as the complexity increases, their limitations become obvious.
Shallow Agents

A shallow agent consists of the fundamental components found in any agentic system:
- The Brain (LLM): The reasoning engine that performs the "think and act" loop popularized by the ReAct framework. The LLM reflects on the problem, decides which actions to take, and iteratively works toward a solution.
- The Body (Tools): The actions the agent can execute — tools that might connect to external APIs, perform mathematical calculations, execute SQL queries on MongoDB or Athena databases, or interact with various services.
The system prompt serves as the agent's instruction manual, defining how it should reason and which actions to take to solve user problems. This architecture proves sufficient for straightforward tasks, making shallow agents widespread across many organizations.
The Limitations of Shallow Agents
However, as task complexity increases, shallow agents reveal critical weaknesses:
1. Forgetting and Implicit Planning
For long-running tasks, agents can lose track of their objectives. The planning is implicit — the agent has a general idea of what needs to be done, but lacks explicit tracking of completed steps versus remaining work.
After working for an extended period, the agent might not even remember:
- What it's currently doing
- Why it's doing it
- Which steps have been completed
- What remains to be done
This implicit planning becomes particularly problematic for complex, multi-step tasks where maintaining context across many reflection steps is essential.
2. Context Window Overflow
Every LLM operates with a maximum context window — a token limit that constrains how much information it can process simultaneously. This context window limit constantly evolve and can go up to 1 000 000 tokens for some models like Claude Sonnet 4.5-1M. These models are obviously more expensive. Complex tasks generate substantial context from: multiple reasoning steps, tool execution outputs, intermediate results, previous conversation history.
As tasks grow in complexity, the context can quickly overflows, forcing the agent to truncate or lose earlier information — potentially including critical details needed to complete the task successfully.
3. Loss of Specialization
Agents perform best when specialized, a single agent handling complex tasks requires many tools and capabilities, transforming it into a generalist "Swiss Army knife."
This loss of specialization manifests as:
- Diluted Context: The prompt becomes a "melting pot" of instructions and context: "You can do this, you can do that. For this action, follow these steps. For that action, do something else..." This complexity confuses the agent, making it less precise in its decision-making
- Reduced Expertise: With attention spread across many domains, the agent can't develop the deep capability needed for sophisticated problem-solving
These limitations aren't theoretical — they represent real barriers to deploying agents for enterprise-grade complex tasks.
Enter the Deep Agents
To overcome these fundamental limitations, two architectural principles are essential:
- Specialization — agents should focus on narrow, well-defined skills rather than becoming generalists
- Structured tracking — the agent must maintain explicit, persistent knowledge of objectives and progress
These principles aren't just nice-to-haves — they're architectural requirements for handling complex tasks effectively.
This is where Deep Agents come in.
The concept, popularized by LangChain and inspired (I guess) by the Orchestrator pattern (popularized by Anthropic) builds on a system of structured planning and orchestration.
The Architecture of Deep Agents

At the heart of a Deep Agent lies an orchestrator agent — the project manager — which defines objectives, creates an explicit plan (a to-do list), and coordinates specialized sub-agents.
The orchestrator has a detailed system prompt that provides precise instructions for:
- Creating and updating the to-do list
- Planning and calling sub-agents
- Using dedicated tools (if the orchestrator needs its own actions)
The To-Do Tool: Formalizing the ReAct framework
This is the cornerstone tool of the Deep Agent pattern. Unlike traditional tools that interact with external systems, the to-do tool manages the agent's internal plan.

See the complete description here Here's how it works:
- First Call: When the orchestrator receives a task, it immediately calls the to-do tool to break down the objective into discrete steps
- Persistent Storage: The to-do list is written to persistent storage — the agent's memory or state — ensuring it survives across the entire task lifecycle
- Status Tracking: Each to-do item has an explicit status:
pending: Not yet started,in progress: Currently being worked on,completed: Finished successfully - Continuous Updates: Throughout execution, the orchestrator regularly calls the to-do tool to check progress and update task statuses
The workflow looks like this:
- Orchestrator checks the to-do list: "What's next?"
- Identifies the first
pendingitem, marks it asin progress - Works on that task (potentially calling a sub-agent)
- Upon completion, marks it as
completedand persists the update - Repeats: "What's next?" → checks the to-do list again
This pattern ensures the agent always knows where it is in the process — even in long-running tasks that might span hours or involve hundreds of reasoning steps.
Persistent Storage: The Foundation
The to-do list must be stored in persistent storage that survives across:
- Individual tool calls
- Sub-agent invocations
- Agent failures and restart
Common storage mechanisms include Agent State - Key-value storage managed by the agent framework, Agent Memory - Conversation and context storage, External State Stores - Databases or file systems for enterprise deployments
This persistence is what differentiates Deep Agents from shallow agents with implicit planning. The plan isn't just "in the agent's head" (context window) — it's written down and accessible at any point in the execution.
In essence, the to-do tool is a formalization of the ReAct framework, transforming implicit reasoning into an explicit, persistent, frequently-updated plan.
Concerning failures handling, the agent is instructed not to invent a new status, but to keep the failing task active (in progress) while creating a new pending task specifically aimed at resolving the current roadblock, maintaining a forward-looking, problem-solving workflow.
Just as humans rely on checklists for complex work, agents benefit from a structured approach.
The Task Tool: Agent Spawner
Once the orchestrator has identified which sub-agent to call (based on the to-do list), it uses the task tool to spawn specialized agents.
The task tool typically accepts:
- Agent selection: Which specialized agent to invoke (e.g., "research_agent", "writer_agent")
- Task description: The specific instructions and context for the sub-agent (prompt)
Each sub-agent is configured with:
- A system prompt: Defines its expertise and behavior
- Dedicated tools: Specialized capabilities relevant to its role
- Model selection: Potentially different model optimized for its task complexity (#finops, #cost-optimization)
File System Tools: Bridging Sub-Agent Results
A critical component of Deep Agents is the ability to pass results between sub-agents efficiently. This is where file system tools become essential.
Common file system tools include: Read: Access file contents, Write: Create new files, Edit: Modify existing files
Why files matter for Deep Agents:
Rather than passing all intermediate results through the orchestrator's context, sub-agents can write their outputs to files:
Searcher Agent #1 → writes to search_results_A.md
Searcher Agent #2 → writes to search_results_B.md
...
Orchestrator knows: "Results are in search_results_*.md"
...
This can be really useful for debugs to check intermediate results and the final output.
This approach provides:
- Context Efficiency: Intermediate results don't bloat the orchestrator's context window
- Clear Data Flow: Each agent knows exactly where to read inputs and write outputs
- Scalability: Can handle arbitrarily large intermediate results without context limits
The orchestrator tracks file paths in its to-do list or state, enabling sub-agents to reference previous work without overwhelming the system's memory.
Sub-Agent Structure
Each sub-agent in a Deep Agent system is itself a complete agent with:
System Prompt (Static): A detailed prompt defining the agent's:
- Role and expertise
- Behavioral guidelines
- Constraints and limitations
- General approach to problems in its domain
This prompt remains consistent across invocations, establishing the agent's core identity.
Task Description (Dynamic): Passed by the orchestrator at runtime, containing:
- The specific task to accomplish
- Relevant context from the to-do list
- References to input files or data
- Expected output format and location
Dedicated Tool Set: Each sub-agent has tools appropriate to its specialization, for example:
| Sub-Agent Type | Common Tools |
|---|---|
| Search Agent | Web search APIs, scraping tools |
| Synthesizer Agent | Often fewer tools, focuses on reasoning |
| Citation Agent | (no tools needed) |
| Data Agent | Database queries (SQL), data transformation |
State Isolation: Each sub-agent has its own isolated state for each invocation. This ensures clean separation between tasks and prevents context pollution from accumulating across multiple calls.
Benefits of the Deep Agent Pattern
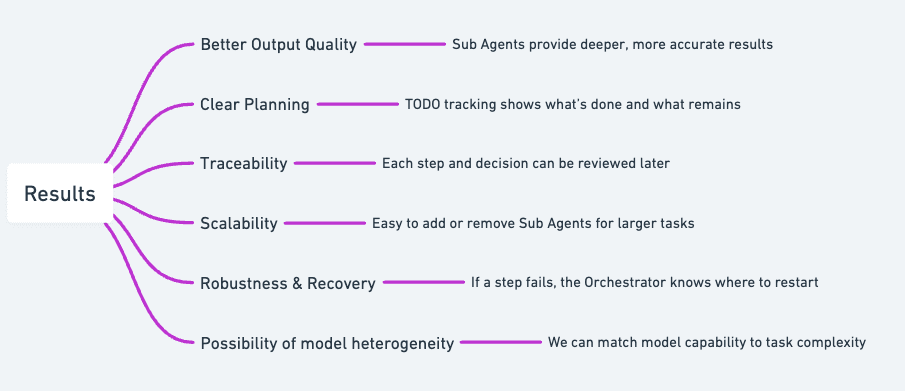
According to research and implementations by Anthropic and others, Deep Agents offer transformative advantages for complex, multi-step tasks:
Enhanced Task Complexity Handling
Deep Agents can tackle significantly more complex problems than shallow agents. The explicit planning and modular architecture allow the system to break down sophisticated challenges into manageable sub-tasks, each handled by a specialized expert.
Traceability and Transparency
Every action and decision is tracked via the persistent to-do structure. At any point, you can inspect:
- Which tasks have been completed
- What's currently in progress
- What remains to be done
- Why each decision was made
This visibility is invaluable for debugging, auditing, and understanding agent behavior.
Scalability: The Microservices Architecture
The orchestrator-sub-agent model mirrors microservices architecture in software engineering. Rather than a monolithic agent doing everything, you have:
- A lightweight orchestrator managing coordination
- Specialized sub-agents, each focused on specific capabilities
- Clean interfaces (file I/O, to-do list) between components
Adding new capabilities is straightforward: Create a new specialized sub-agent, register it with the orchestrator, and update the planning logic. No need to retrain or restructure the entire system.
Robustness and Recovery
When a task fails in a shallow agent, the entire process often needs to restart from scratch. With Deep Agents, failure handling is granular:
- The orchestrator knows exactly which task is being worked on when failure occurs
- It can retry just that specific task with a different approach
- Other completed tasks remain intact
- The agent can implement sophisticated retry strategies based on task status tracking
- Failed tasks can be marked explicitly, enabling automated recovery workflows
This structured approach to task tracking dramatically improves reliability for production systems.
Maintained Specialization
Each sub-agent maintains focused expertise:
- Search agents: Excel at web research with specialized search tools and APIs
- Citation agents: Specialize in reference formatting
- Data agents: Expert at querying databases and processing results
Unlike a Swiss Army knife agent that's mediocre at everything, each component is exceptional at its specific function.
Context Engineering
By distributing work across sub-agents and using file storage for intermediate results, Deep Agents allows to manage the context window limitations that plague shallow agents. Each sub-agent works within its own context boundary, and the orchestrator maintains only the high-level plan and file references.
The structured on-the-fly orchestration enables agents to handle deeper reasoning and longer tasks without losing coherence or efficiency.
The Power of Model Selection: Microservices for Agents
One of the most compelling advantages of Deep Agents is the ability to use different models for different sub-agents based on task complexity. This approach directly mirrors microservices architecture in software engineering.
The Principle: Right-Size Your Models
Not every task requires a frontier model. Consider the spectrum:
- Simple, deterministic tasks (extracting data, formatting data, making simple API calls): These can use lighter, faster models
- Complex reasoning tasks (strategic planning, synthesis, nuanced decision-making): These benefit from powerful, sophisticated models
In a Deep Agent system:
- The orchestrator typically uses a strong model (it needs sophisticated planning capabilities), e.g. Claude Sonnet 4.5
- Specialized sub-agents use models appropriate to their task complexity, e.g. Claude Haiku 4.5, Fine Tuned Small Language Models
Two Major Benefits:
Cost Efficiency
By matching model capability to task complexity, you can reduce operational costs dramatically:
- Running simple sub-agents on lighter models instead of frontier models saves significant money at scale
- The orchestrator and a few critical sub-agents use expensive models, but most of the work happens on cheaper tiers
- Cost reductions of 50-80% are achievable with thoughtful model selection
Performance Optimization
Lighter models respond faster, reducing overall system latency:
- Smaller models typically have much faster response times
- Frontier models with extended capabilities take longer but provide deeper reasoning
- For tasks that don't need advanced reasoning, lighter models provide significant speed improvements
This is exactly how modern software systems are built:
- You don't use the same infrastructure for every service
- A simple API gateway doesn't need the same compute as a machine learning inference service
- Right-sizing resources based on requirements is fundamental to scalable architecture
Deep Agents bring this principle to the agentic world: specialized, right-sized components working together in a coordinated system, each optimized for its specific role — both in capabilities and cost.
When Not to Use Deep Agents
Despite their advantages, Deep Agents are not a universal solution. Understanding when not to use them is as important as knowing when they excel.

Simple, Straightforward Tasks
For basic operations that a shallow agent can handle in a few steps, the overhead of Deep Agent architecture is unnecessary (Answering simple questions from a knowledge base, Performing basic calculations or data lookups, Single-step API interactions
Use a standard shallow agent — it's faster, simpler, and more cost-effective.
- Deterministic Workflows: When you already know the exact sequence of steps required (X → Y → Z), you don't need dynamic planning (ETL pipelines with fixed stages, Standard data processing workflows, Scheduled tasks with predetermined logic
Latency-Critical Applications
The Deep Agent pattern introduces overhead (Initial planning phase (creating the to-do list), Frequent to-do updates during execution, Spawning and coordinating multiple sub-agents, File I/O for intermediate results)
This adds latency — potentially seconds or more depending on system complexity.
For real-time or low-latency requirements (e.g., chatbot responses, API endpoints with strict SLAs), prefer shallow agents or even non-agentic approaches (Webhooks, API endpoints, Scheduled tasks)
Cost-Sensitive, High-Volume Operations
While Deep Agents can be cost-optimized through model selection, they still make more LLM calls than shallow agents (Multiple orchestrator calls for planning and updating, Each sub-agent invocation, Synthesis and coordination steps)
For high-volume, cost-sensitive applications where margins are tight, simpler approaches may be more economical.
The Decision Tree:
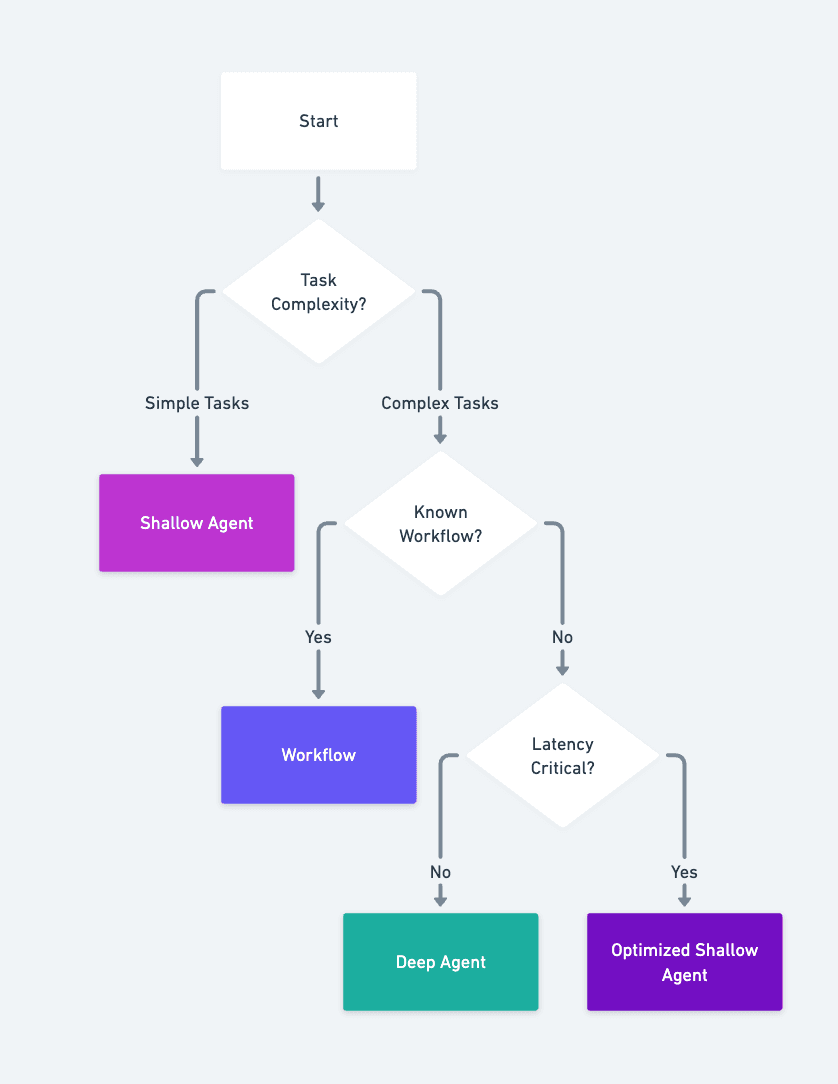
Obviously, this is a simplified decision matrix, and the real world is more complex, the rule is:
Use the simplest solution that meets your needs. There is no one-size-fits-all solution. Test, iterate, and optimize.
Implementing Deep Agents with Strands
The Deep Agent pattern can be implemented with any agent framework that provides the necessary primitives. To demonstrate these concepts in practice, I've built a reference implementation using Strands inspired by LangChain implementation, leveraging its native capabilities for state management, tool orchestration, and model flexibility.
The implementation is available on GitHub: strands-deep-agents
Why Strands for Deep Agents?
Strands provides the key primitives needed for Deep Agent patterns:
- Persistent State Management: Built-in agent state that survives across requests, essential for maintaining TODO lists
- Rich Tool Ecosystem: Both a flexible tool system and community packages (like
strands-agents-tools) for file operations - Agent-as-Tool Pattern: Native support for spawning sub-agents and using them as tools
- Model Flexibility: Easy per-agent model configuration for cost optimization
- Async Support: Full async/await patterns for concurrent sub-agent execution
Core Pattern Implementation
The implementation follows the Deep Agent pattern by providing three foundational tools:
- Planning Tool: Manages the TODO list in persistent agent state and thus in memory see:

Persisted Agent State Example - File System Tools: Enable inter-agent communication via file I/O
- Task Delegation Tool: Spawns specialized sub-agents with isolated contexts
Example Usage
from strands_deep_agents import create_deep_agent
# Create a deep agent with specialized sub-agents
agent = create_deep_agent(
instructions="You are a helpful assistant that excels at complex tasks.",
subagents=[
{
"name": "researcher",
"description": "Conducts thorough research",
"prompt": "You are a research specialist.",
},
{
"name": "writer",
"description": "Creates polished content",
"prompt": "You are a skilled writer.",
}
]
)
# The agent automatically uses the Deep Agent pattern
result = agent("Create a comprehensive report on renewable energy trends in the last 10 years")
You can see a full DeepSearch implementation here
Strands-Specific Implementation Notes
For those interested in the technical details of this particular implementation:
- State Structure: Uses a custom
DeepAgentStatewithtodos(task list) - Status Support: Implements three task statuses:
pending,in_progress,completed - Tool Access: Tools receive a
ToolContextparameter providing access to agent state - Session Persistence: Supports saving/loading agent state across application restarts
- Model Options: Defaults to Claude Sonnet 4, with per-sub-agent model overrides
- Execution Modes: Supports both parallel and sequential tool execution
See the GitHub repository for complete documentation on the Strands-specific implementation details.
The Evolution Continues
The rise of Deep Agents marks a natural but significant progression in the agentic era — a sophisticated evolution building on the foundations laid by frameworks like ReAct and Anthropic's Orchestrator Pattern.
Understanding the Lineage
Deep Agents didn't emerge from nowhere. They represent the maturation of ideas that have been developing over the past few years:
- ReAct Framework: Introduced the "reasoning and acting" loop that became fundamental to agentic systems
- Orchestrator Pattern: Popularized by Anthropic, demonstrated the power of coordinating multiple specialized components
- Deep Agents: Formalized by LangChain, combines orchestration with explicit, persistent planning — the missing piece that enables truly complex task handling
This evolution shows how the AI community iterates and improves: each pattern addresses limitations of its predecessors while building on their strengths.
Key Principles to Remember
Three fundamental insights underpin successful agentic systems:
- Specialization Matters: Focused agents with clear expertise outperform generalist "Swiss Army knife" agents
- Explicit Tracking is Essential: For complex tasks, implicit reasoning fails. Persistent, structured plans (to-do lists) keep agents on track
- Choose the Right Pattern: Match your architecture to your problem's complexity, not the other way around
- Context Engineering is key to avoid context window limitations, maintain focus, coherence and efficiency.
Looking Forward
The agentic era is still remarkably young — we're witnessing the equivalent of the early days of microservices or containerization. Patterns are emerging, best practices are solidifying, but the field remains dynamic and fast-evolving.
When building agents:
- Study existing patterns — don't reinvent what others have already refined
- Explore actively — experiment with different architectures to understand their trade-offs
- Stay updated — new patterns and improvements emerge constantly
- Share learnings — the community benefits from practical experiences and lessons learned
The evolution from shallow to deep agents demonstrates that we're moving toward more structured, maintainable, and production-ready agentic systems.
The future belongs to those who can orchestrate specialized intelligence effectively.
As agents become increasingly central to how we build software, understanding these patterns — and knowing when to apply each — will be a defining skill for the next generation of AI engineers.
Complete MindMap
I know it's a bit long, but I hope you found it useful. I wanted to explain the concepts in details and show a practical implementation. Feel free to reach out to me if you have any questions or feedback.
PA,